
I’ve had building a RAG on my to-do list for a while. Lately, I’ve been experimenting with Groq, which has consistently impressed me with its inference speed. It’s been over four months since I cancelled my ChatGPT Plus subscription and switched to BoltAI, where I can access leading models like GPT-4, Llama-3.70B, Claude Opus, and Mistral-8x7b at a fraction of the cost. What I appreciate about BoltAI is its well-designed graphical user interface, which allows me to easily connect with multiple foundational models via API.
Whats a RAG?
Retrieval Augmented Generation involves injecting targeted data sets into the model to create a customized GPT that can engage in conversation with you. It’s crucial to understand that foundational models like GPT4 or Llama3 have been trained on vast amounts of internet data, but they may lack specific information stored on your hard disk, such as your bank statements, deposits, portfolio holdings, insurance certificates, provident fund holdings, and so on.
Consider envisioning a scenario where you require a personal finance aide to guide you regarding your investments. This assistant would analyze whether your portfolio is heavily focused on specific regions, industries, investment firms, or if it is influenced by recent events (requiring real-time search). It would inform you about potential risks associated with your holdings, such as exposure to volatile currencies like USD forex, and advise you on necessary adjustments.
All of this can be achieved if you give the foundational model specific set of data that it does not have and this is achieved with RAG
I then came across this tweet from @ashpreetbedi and jumped into building a RAG
The set up was breeze. I have just copied the cookbook here for ease and added some comments that I modified/adapted
Autonomous RAG with Llama3 on Groq. This cookbook shows how to do Autonomous retrieval-augmented generation with Llama3 on Groq.
For embeddings we can either use Ollama or OpenAI. – I used OpenAI
https://github.com/phidatahq/phidata – Download this repo and run the following instructions
-
Create a virtual environment python3 -m venv ~/.venvs/aienv source ~/.venvs/aienv/bin/activate
-
Export your GROQ_API_KEY export GROQ_API_KEY=***
-
Use Ollama or OpenAI for embeddings Since Groq doesnt provide embeddings yet, you can either use Ollama or OpenAI for embeddings.
To use Ollama for embeddings Install Ollama and run the nomic-embed-text model ollama run nomic-embed-text To use OpenAI for embeddings, export your OpenAI API key export OPENAI_API_KEY=sk-***
- Install libraries pip install -r cookbook/llms/groq/auto_rag/requirements.txt
- Run PgVector Install docker desktop first.
Run using a helper script
./cookbook/run_pgvector.sh
OR run using the docker run command
docker run -d
-e POSTGRES_DB=ai
-e POSTGRES_USER=ai
-e POSTGRES_PASSWORD=ai
-e PGDATA=/var/lib/postgresql/data/pgdata
-v pgvolume:/var/lib/postgresql/data
-p 5532:5432
–name pgvector
phidata/pgvector:16
6. Run Autonomous RAG App
streamlit run cookbook/llms/groq/auto_rag/app.py
Open localhost:8501 to view your RAG app.
Add websites or PDFs and ask question.
Example: I added my one of mutual fund portfolio holding PDF
and asked the following questions;
Lets Auto RAG
Just for reference – The portfolio PDF contained only the following info
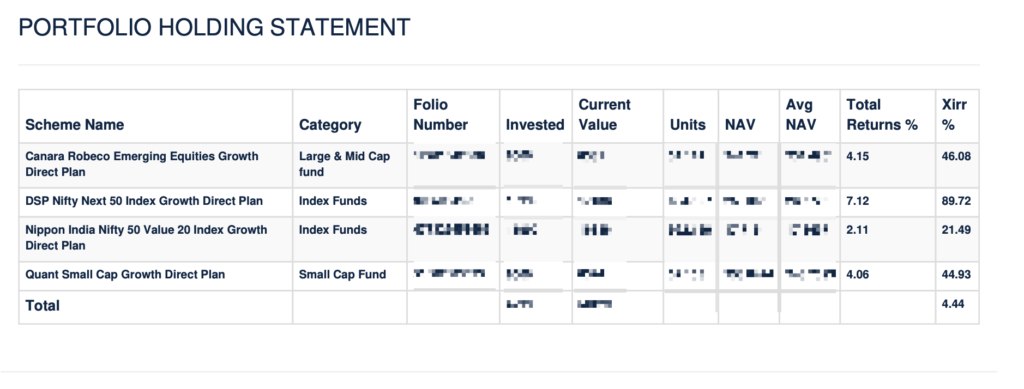
What are my portfolio holdings?

Straight forward reading from the pdf right?
Can you tell me which stocks are held by 4 mutual funds in my portfolio?

This is awesome. I would have to search & browse 1-2 websites min, 3-5 clicks for each fund and then would get this info. Note that I am getting all of the holdings in one single view. UX is marginally better, but no graphs or pie charts, but guess I could improve this with some prompt engineering.
Give a % stock holding overlap in the 4 funds ?

Now this is mind-boggling! I would need to fire-up num py and upload the detailed pdf holding above step and run a program and that would get me the above info. Now I get all of it with a prompt. Just what I need!
Now let’s look under the hood what agent flow is being triggered in the “auto rag”
This is the instruction that powers the initiation of the GPT.
assistant.py is the file that triggers a agent flow.
description="You are an Assistant called 'AutoRAG' that answers questions by calling functions.",
instructions=["First get additional information about the users question.",
"You can either use the `search_knowledge_base` tool to search your knowledge base or the `duckduckgo_search` tool to search the internet.",
"If the user asks about current events, use the `duckduckgo_search` tool to search the internet.",
"If the user asks to summarize the conversation, use the `get_chat_history` tool to get your chat history with the user.",
"Carefully process the information you have gathered and provide a clear and concise answer to the user.",
"Respond directly to the user with your answer, do not say 'here is the answer' or 'this is the answer' or 'According to the information provided'",
"NEVER mention your knowledge base or say 'According to the search_knowledge_base tool' or 'According to {some_tool} tool'.",
],search_knowledge_base – this is what the model builds in the pgvector db when you upload a PDF or web URL
duckduckgo_search – The instruction then tells the gpt to search the internet if the information is not available in search_knowledge_base
Rest of the instructions are carefully crafted to make the experience more natural and conversation like.
I could setup the whole auto RAG in less than 20 mins. Pleased with how Ashpreet has made the setup so developer friendly.
I plan to play more with it and maybe build a personal dashboard and dump all my local data in there and use it as a personal assistant.
I wont be surprised if Rabbit R1 has a similar agent flow under the hood. It has already been mocked enough on X that it is an android app with some python code calling api’s.