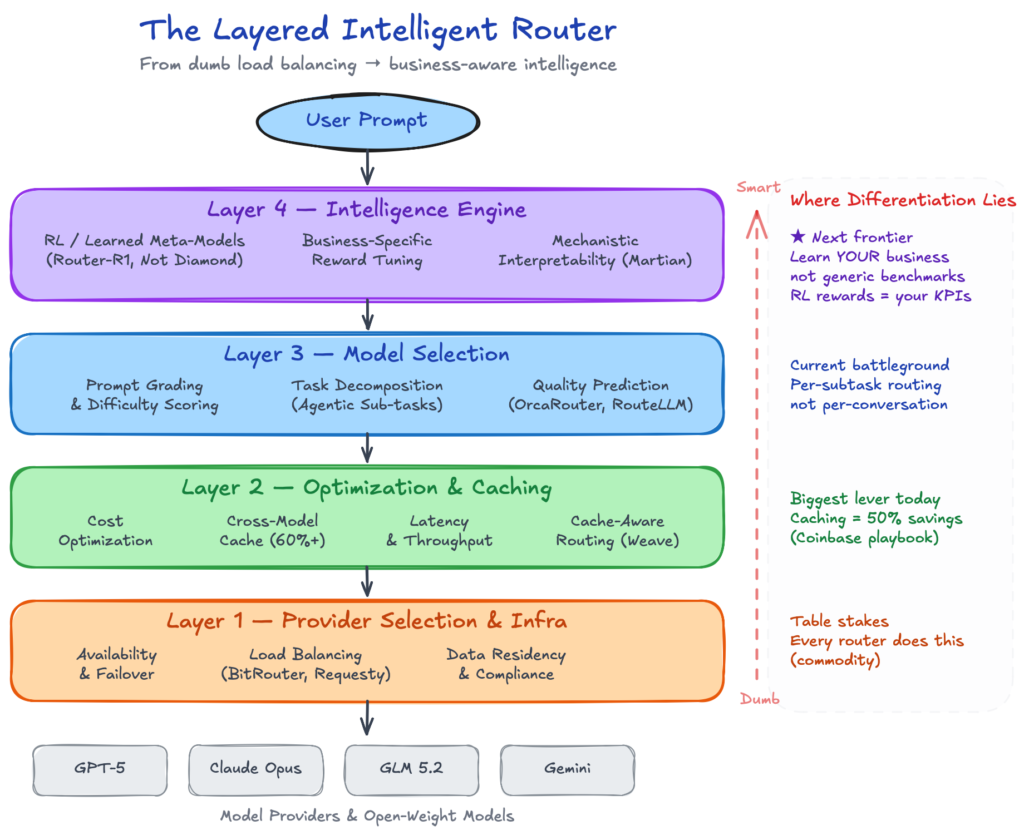
Every time you send a prompt to an AI app, something behind the scenes has to decide which model inference server actually answers it. Most people never think about this. But that decision — the “router” — is quietly turning into one of the most important pieces of the AI stack. This is a walkthrough of what routers actually do today, what’s still shallow about them, and where the smart money says they’re headed next.